So we are seeing more and more cases of malicious code injected into shared models, skills, tool, agents, and projects. I had a case where a shared model had a number of malicious code blocks that the users had not noticed due to the size of the codebase. At the time of this writing, we are seeing proliferation of malicious skills and prompts with a variety of payloads. When run in an IDE with AI tools, much of these produce execution and C2 activity that is detectable if something was watching closely enough. The challenge is that these events will be in a haystack of benign process and network events from tasks the AI tools were given permission for by the user. One of the purposes of the ODR (open DR) project is to hunt for this class of threat activity using anomaly detection techniques and a learning informed detection pipeline that is continuously updated.
One reason to run these hunts at the local level, in addition to conventional SOC and SIEM operations, is that the definition of what normal looks like, for a particular IDE, is largely in the head of the developer. Another reason is that much of the context is on the endpoint where the activity took place, and all of that state cannot generally be logged to a SIEM due to data volume and cost. At the same time, devs cannot monitor every action taken by their tools, and they are not trained in what to look for. This feels like a job for an autonomous agent pack.
Smith is an autonomous agent pack that will process most alerts and anomaly detections generated by ODR (open DR, also in this GitHub org.) ODR mainly looks for strange things happening in your AI dev tools at present but Smith will process most alerts generated by ODR. There is a show and tell video here: https://youtu.be/lsh3JRne9sg and the project lives in a repo here: https://github.com/opendr-io/agentic-park/tree/main/smith
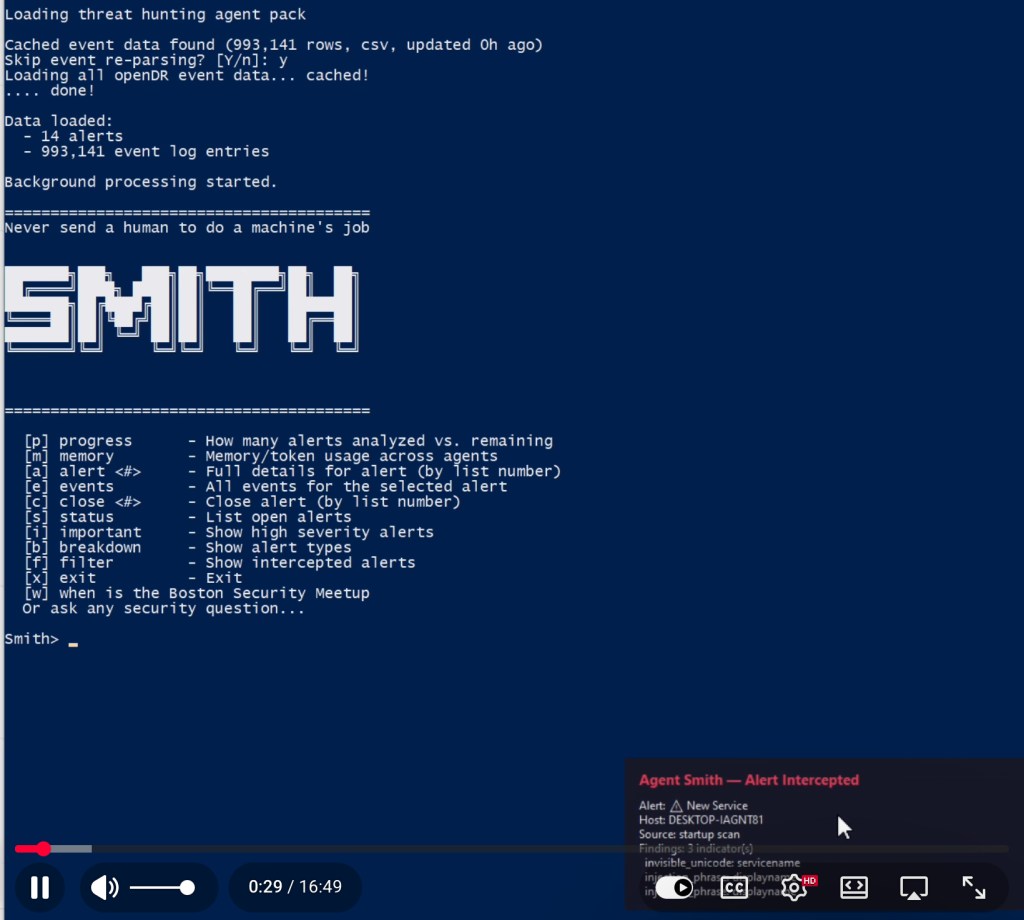
Smith processes raw event and alert data from the ODR (open DR) project in order to investigate alerts and anomaly detections. It outputs an analysis of each alert. It lets you know when it thinks it has a high confidence detection and engages you in a collaborative analysis conversation in order to work out whether the detected activity is benign and expected or unexpected and potentially malicious.
Some sample alert data is provided so that it can do something out of the box. Sample event data is not provided due to its size, and the need to sanitize it, but can be generated by running openDR. It has a filter layer to try to stop prompt injections from reaching the agents and one filter test case alert is included in the sample data; you will see it get “intercepted” by the filter. That is an interesting area of research and we would like to hear from both offensive and defensive researchers as we add more filtering techniques and more detections.
